def find_max_crossing_subarray(A, low, mid, high): """ 求跨越两个数组的最大字数组 :param A: :param low: :param mid: :param high: :return: """ left_sum = A[mid] left_index = mid sum = 0 for left in range(mid, low - 1, -1): sum = sum + A[left] if sum > left_sum: left_sum = sum left_index = left
right_sum = A[mid + 1] right_index = mid + 1 sum = 0 for right in range(mid + 1, high + 1): sum = sum + A[right] if sum > right_sum: right_sum = sum right_index = right return left_index, right_index, left_sum + right_sum
import random class Random_quick_sort(object): def _randomized_partition(self, alist, p, r): i = random.randint(p, r) alist[i], alist[r] = alist[r], alist[i] return self._partition(alist, p, r) def _partition(self, alist, p, r): i = p-1 x = alist[r] for j in range(p, r): if alist[j]<=x: i += 1 alist[i], alist[j] = alist[j], alist[i] alist[i+1], alist[r] = alist[r], alist[i+1] return i+1 def _quicksort(self, alist, p, r): if p<r: q = self._randomized_partition(alist, p, r) self._quicksort(alist, p, q-1) self._quicksort(alist, q+1, r) def __call__(self, sort_list): self._quicksort(sort_list, 0, len(sort_list)-1) return sort_list if __name__ == "__main__": sort_list = [4,2,7,3,1,9,33,25,46,21,45,22] print sort_list random_quick = Random_quick_sort() print random_quick(sort_list)
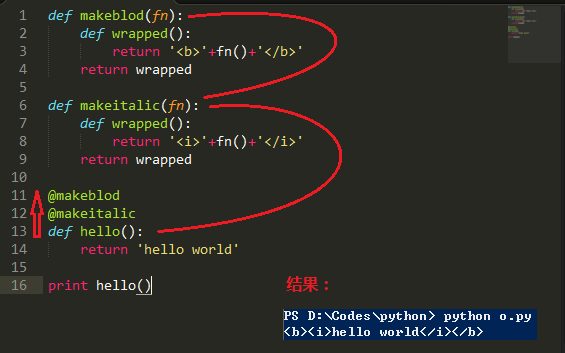
Python风格快速排序算法
1 2 3 4 5 6 7 8 9 10
def quick_sort_2(sort_list): if len(sort_list)<=1: return sort_list return quick_sort_2([lt for lt in sort_list[1:] if lt<sort_list[0]]) + \ sort_list[0:1] + \ quick_sort_2([ge for ge in sort_list[1:] if ge>=sort_list[0]]) if __name__ == "__main__": sort_list = [4,2,7,3,1,9,33,25,46,21,45,22] print sort_list print quick_sort_2(sort_list)
class Counting_sort(object): def _counting_sort(self, alist, k): alist3 = [0 for i in range(k)] alist2 = [0 for i in range(len(alist))] for j in alist: alist3[j] += 1 for i in range(1, k): alist3[i] = alist3[i-1] + alist3[i] for l in alist[::-1]: alist2[alist3[l]-1] = l alist3[l] -= 1 return alist2 def __call__(self, sort_list, k=None): if k is None: import heapq k = heapq.nlargest(1, sort_list)[0] + 1 return self._counting_sort(sort_list, k) if __name__ == "__main__": sort_list = [4,2,7,3,1,9,33,25,46,21,45,22] print sort_list counting = Counting_sort() print counting(sort_list)
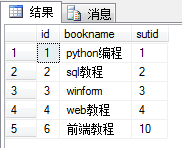
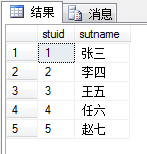
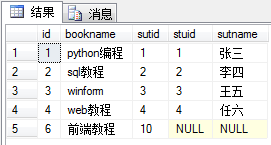
内连接:内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值。 select * from book as a,stu as b where a.sutid = b.stuidselect * from book as a inner join stu as b on a.sutid = b.stuid
内连接可以使用上面两种方式,其中第二种方式的inner可以省略。
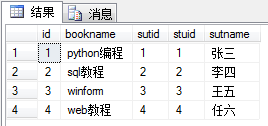
其连接结果如上图,是按照a.stuid = b.stuid进行连接。
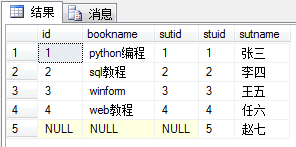
外连接
左联接:是以左表为基准,将a.stuid = b.stuid的数据进行连接,然后将左表没有的对应项显示,右表的列为NULL select * from book as a left join stu as b on a.sutid = b.stuid
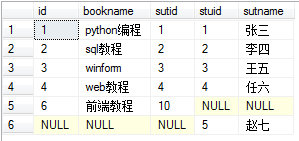
右连接:是以右表为基准,将a.stuid = b.stuid的数据进行连接,然以将右表没有的对应项显示,左表的列为NULL select * from book as a right join stu as b on a.sutid = b.stuid
全连接:完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。 select * from book as a full outer join stu as b on a.sutid = b.stuid
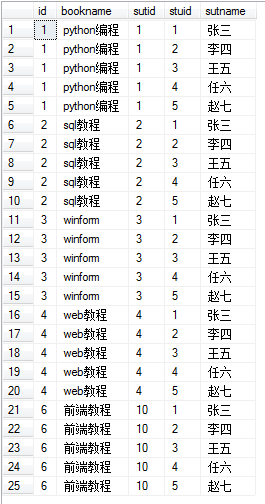
交叉连接
交叉连接:交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。 select * from book as a cross join stu as b order by a.id