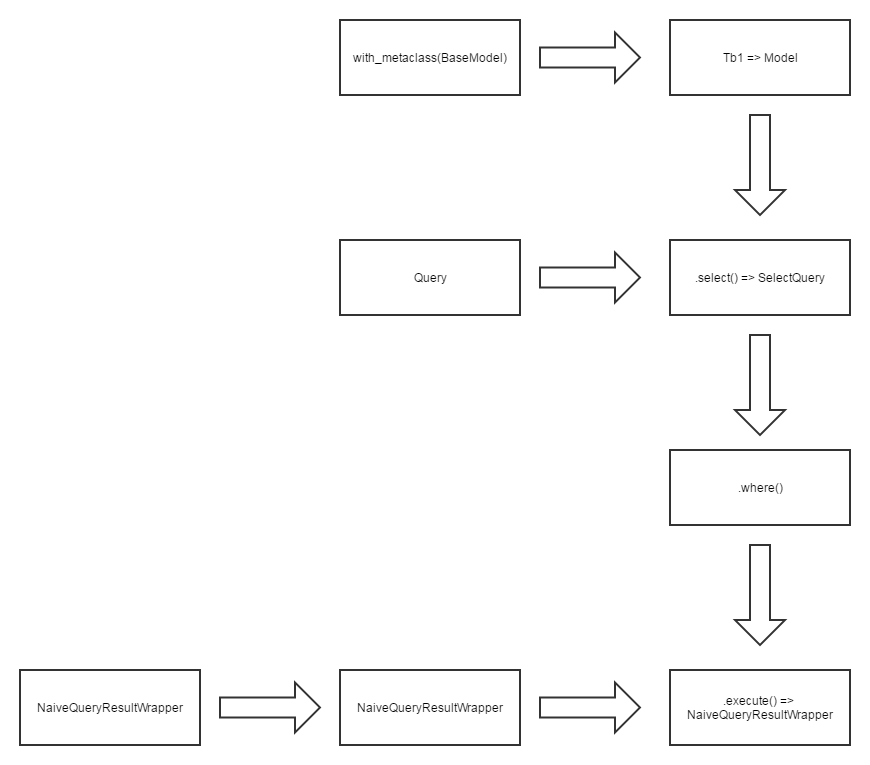
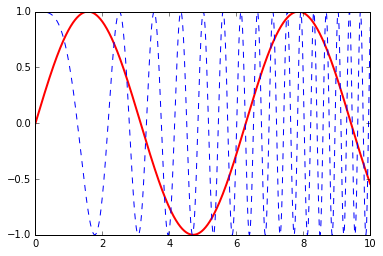
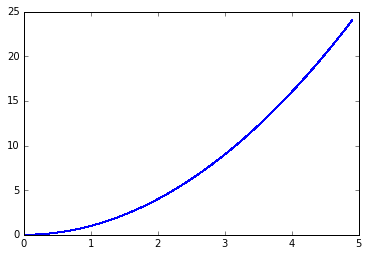
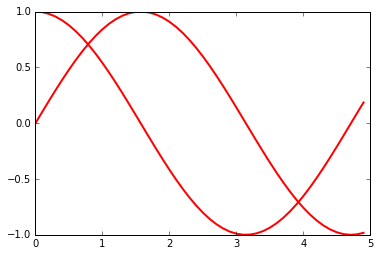
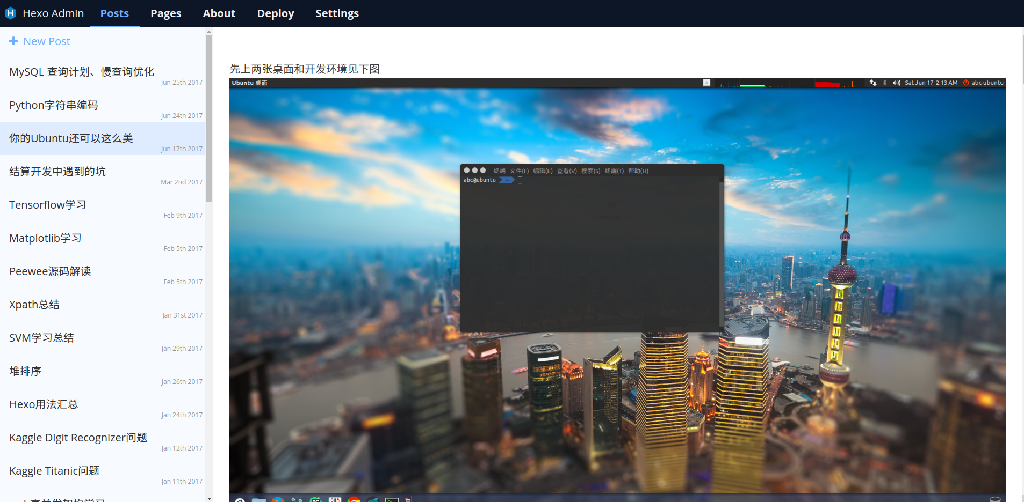
/usr/lib/python2.7/dist-packages/matplotlib/figure.py:397: UserWarning: matplotlib is currently using a non-GUI backend, so cannot show the figure
"matplotlib is currently using a non-GUI backend, "
defright_node(index): """右子节点""" return2 * index + 1
defmax_heapify(array, index): """维护最大堆""" left = left_node(index) right = right_node(index) if left <= len(array) and array[left - 1] > array[index - 1]: largest = left else: largest = index if right <= len(array) and array[right - 1] > array[largest - 1]: largest = right if largest != index: array[index - 1], array[largest - 1] = array[largest - 1], array[index - 1] max_heapify(array, largest)
defbuild_max_heap(array): """建最大堆""" for index inrange(len(array) / 2, 0, -1): max_heapify(array, index)
alias cnpm="npm --registry=https://registry.npm.taobao.org \ --cache=$HOME/.npm/.cache/cnpm \ --disturl=https://npm.taobao.org/dist \ --userconfig=$HOME/.cnpmrc"
# Or alias it in .bashrc or .zshrc $ echo '\n#alias for cnpm\nalias cnpm="npm --registry=https://registry.npm.taobao.org \ --cache=$HOME/.npm/.cache/cnpm \ --disturl=https://npm.taobao.org/dist \ --userconfig=$HOME/.cnpmrc"' >> ~/.zshrc && source ~/.zshrc