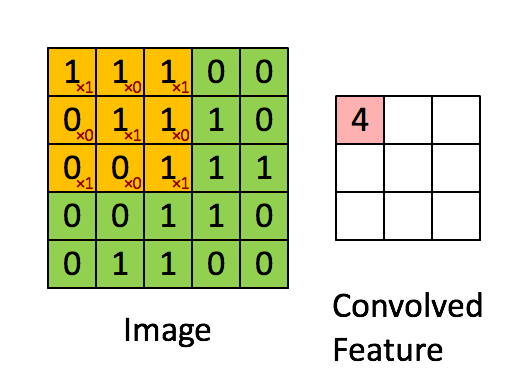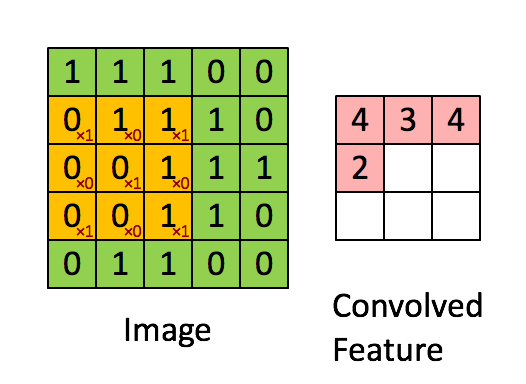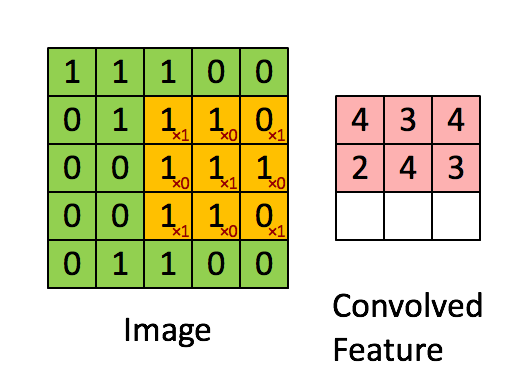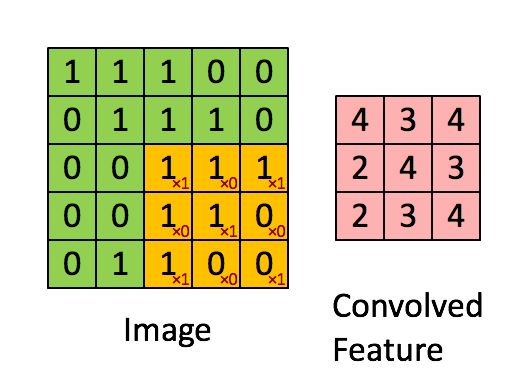
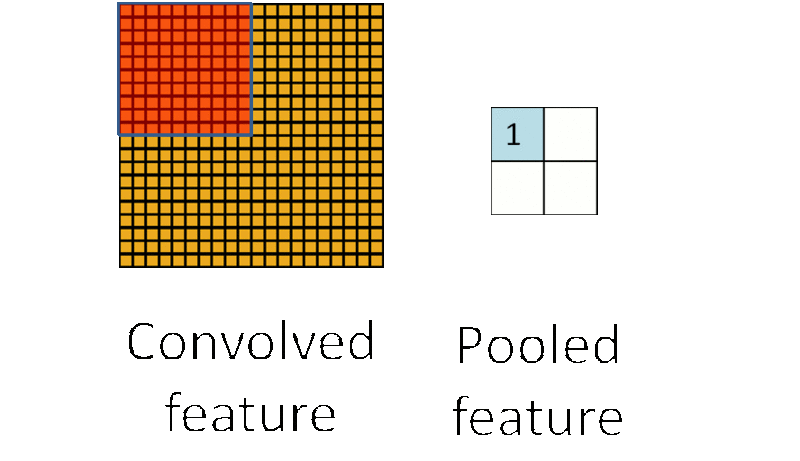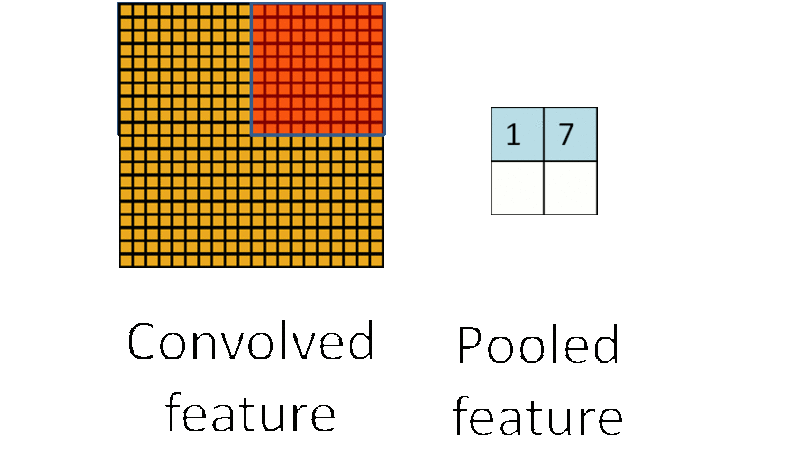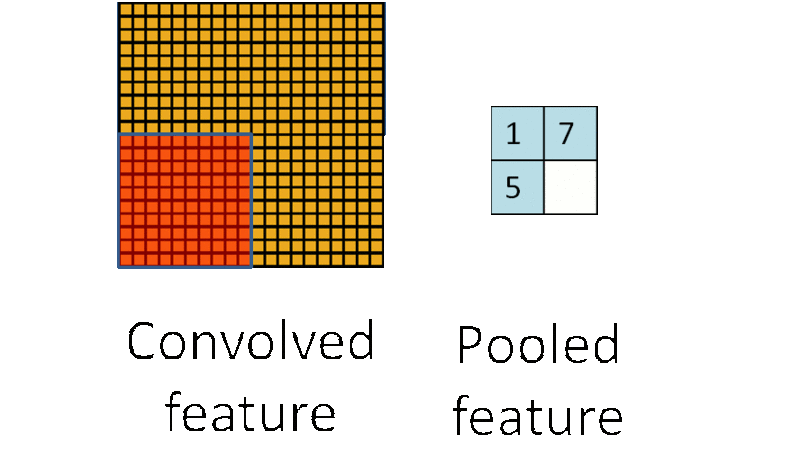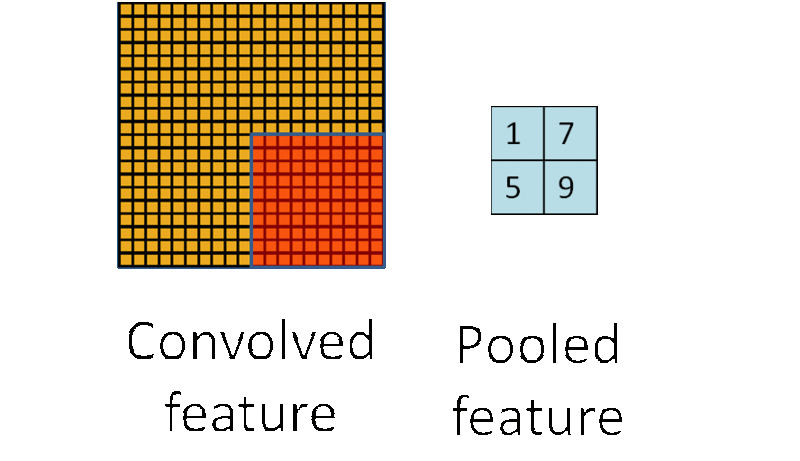
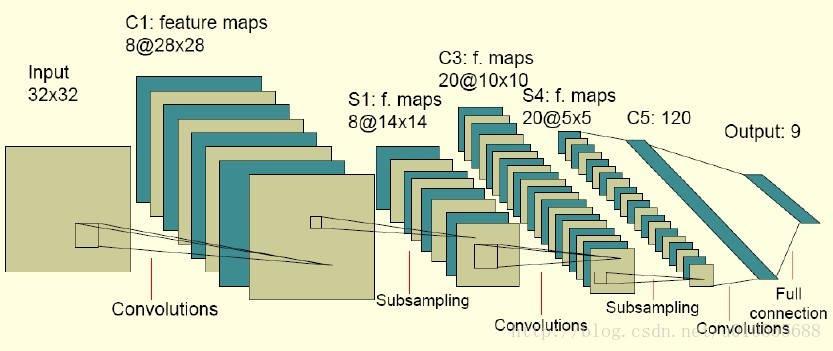
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
| import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
if avg_class is None:
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
else:
layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1))
return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2)
x = tf.placeholder(tf.float32, [None, INPUT_NODE])
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE])
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
y = inference(x, None, weights1, biases1, weights2, biases2)
global_step = tf.Variable(0, trainable=False)
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
regularization = regularizer(weights1) + regularizer(weights2)
loss = cross_entropy_mean + regularization
learnging_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE, global_step, mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY)
train_step = tf.train.GradientDescentOptimizer(learnging_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op()
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
if __name__ == "__main__":
with tf.Session() as sess:
tf.global_variables_initializer().run()
validate_feed = {x: mnist.validation.images,
y_: mnist.validation.labels}
test_feed = {x: mnist.test.images, y_: mnist.test.labels}
for i in range(TRAINING_STEPS):
if i % 1000 == 0:
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
print "训练轮数:", i, ",准确率:", validate_acc * 100, "%"
xs, ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_op, feed_dict={x: xs, y_: ys})
test_acc = sess.run(accuracy, feed_dict=test_feed)
print "训练轮数:", TRAINING_STEPS, ",准确率:", test_acc * 100, "%"
|